About
I’m a Software Engineer at Zenact AI, where I build AI agents, intelligent workflows, and backend systems.
I have hands-on experience in backend engineering, automation, and scalable system design, working with startups across AI, defence, and healthcare.
I enjoy understanding how complex systems work end-to-end, and I’m naturally curious about technology, products, and large-scale problem-solving.
See you sometime,
Cheers:)
Work Experience

Zenact AI
Software Engineer
• Implemented a backend service that allows users to upload mobile application binaries for testing, including S3 storage integration and metadata persistence (user, organization, timestamps, and asset details) in DynamoDB.
• Designed and implemented a scalable, decoupled Report Generation Service using a Fan-Out architecture: fetched test results from DynamoDB, formatted QA reports, and published events via AWS SNS to AWS SQS queues for async processing.
• Developed an independent Notification Service for asynchronous report delivery: AWS Lambda workers consumed AWS SQS messages to send notifications via AWS SES (email) and Slack API, ensuring high availability and failure isolation.
• Built a retrieval service that returns all uploaded application assets and associated metadata for a given organization, enabling smooth selection and reuse in automated testing workflows.
• Built an LLM-agnostic agent layer enabling seamless dynamic switching between OpenAI, Groq and Gemini through environment variables, ensuring zero downtime and uninterrupted operations.

Tennr (YC W23)
Implementation Engineer (Intern)
• Implemented end-to-end healthcare automation workflows, processing scanned documents and faxes with Tennr’s RaeLM to extract structured data and populate client EHR systems, improving accuracy and reducing manual effort.
• Engineered workflow optimizations that reduced approval and processing delays by 20% by improving triage rules, error-handling branches, and follow-up logic for missing or incomplete documents, accelerating reimbursement cycles.
• Designed workflow logic for document classification, data extraction, patient qualification, and insurance verification, ensuring accurate routing and reliable population of client EHR and billing systems.
• Monitored live automation pipelines across multiple healthcare clients and resolved workflow-level issues, configuration bugs, and edge-case failures, maintaining 99.5% uptime for all assigned accounts.
• Collaborated with operations and engineering teams to validate outputs, refine extraction rules, and improve system reliability, ensuring consistent performance for clinics, DMEs, and specialty practices.
• Delivered client-specific implementations for Neb Medicals, Aveanna, Gammie, Lymphacare, and other healthcare providers, tailoring automation logic to their documentation formats, reimbursement workflows, and operational needs.

Neuralix AI
Software Engineer (Intern)
• Engineered scalable backend services for a real-time situational awareness platform supporting defense operations, ingesting incoming operational data and delivering processed insights to monitoring dashboards and command interfaces.
• Designed and implemented RESTful APIs using FastAPI to ingest and serve structured operational data, leveraging PostgreSQL for persistent storage with query optimization and strategic indexing to ensure low-latency responses.
• Implemented asynchronous task processing using Celery with Redis as a message broker to handle concurrent data workloads.
• Collaborated with cross-functional teams, senior engineers, and stakeholders to refine backend logic, troubleshoot issues, and improve system reliability and scalability.


Skills
Contributions
Giving back to the community through code and documentation.
📌 Open edX Credentials: Deprecated Feature Flag Cleanup
Contributed to the Open edX Credentials by removing a deprecated waffle flag (USE_CERTIFICATE_AVAILABLE_DATE).
Cleaned up unused definitions, stale references, and outdated comments from the repo.
Ensured full consistency by verifying that no remaining references to the flag existed across the project.
Helped reduce technical debt and simplify the configuration layer.
Improved code readability and maintainability for future contributors and maintainers.
📌 Implemented Beta Likelihood Support for Bounded Data Modeling.
Contributed Beta likelihood support to Prophetverse, a Bayesian extension of Meta’s Prophet time-series forecasting library.
Added first-class support for modeling bounded data (0–1) such as CTR, conversion rates, and retention ratios.
Implemented BetaTargetLikelihood with stable link functions, smooth clipping, and NumPyro-based likelihood calculations.
Added the new ProphetBeta model and integrated it across the likelihood registry.
Wrote comprehensive unit tests and updated documentation with mathematical details.
Improves Prophetverse’s modeling flexibility and removes the need for workarounds like logit transforms.
Check out my work
A collection of things I've built and worked on.
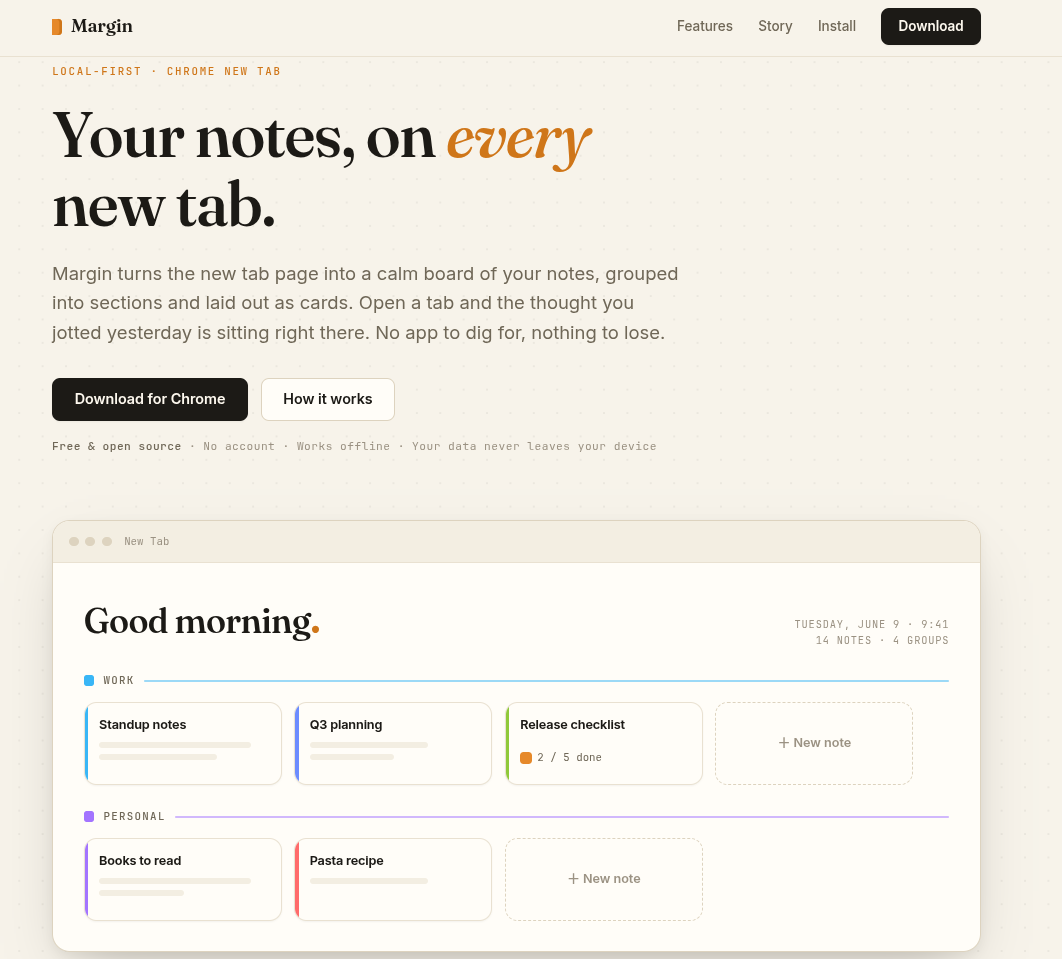
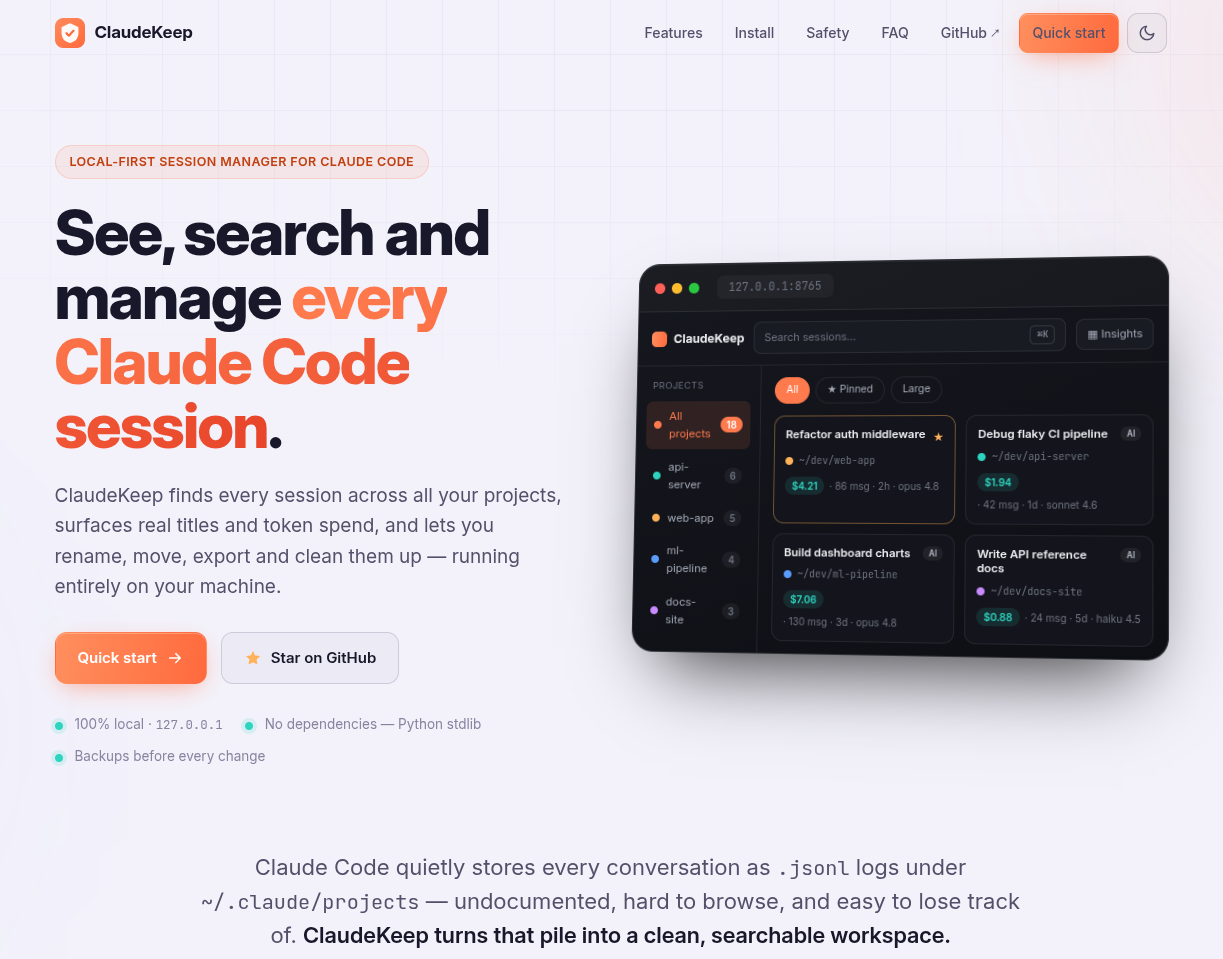
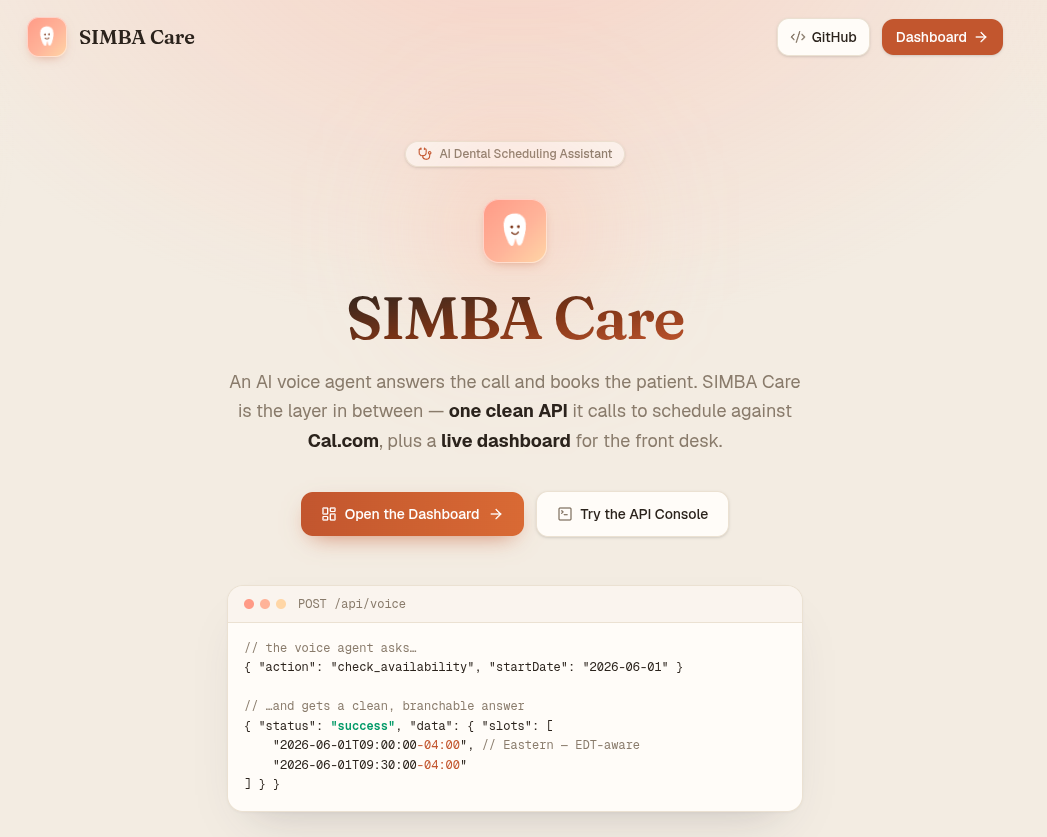
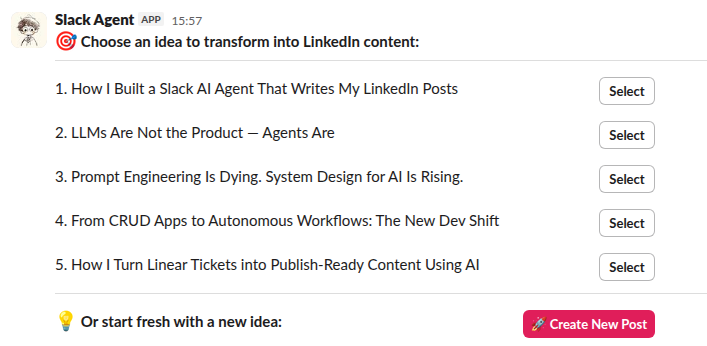
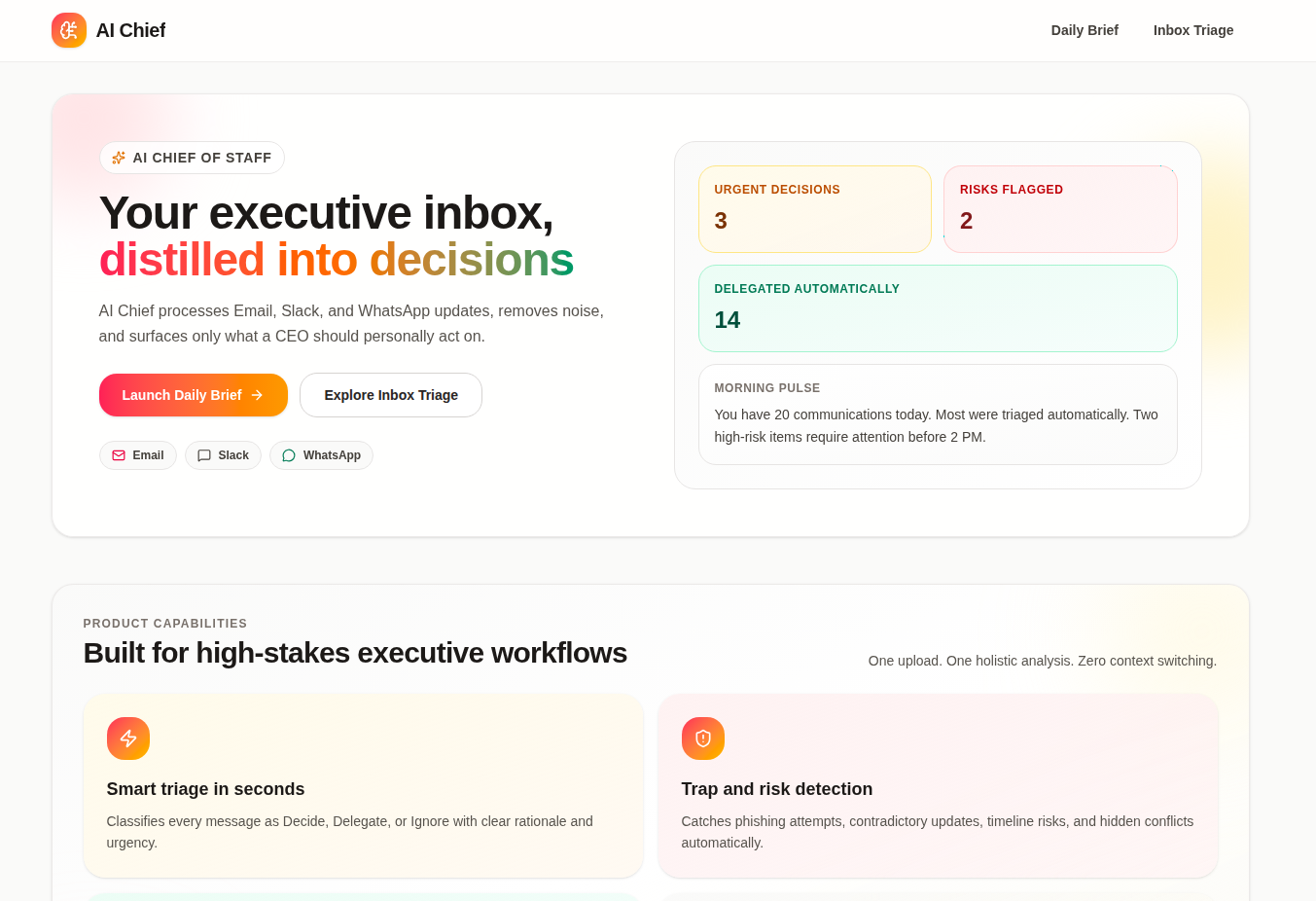
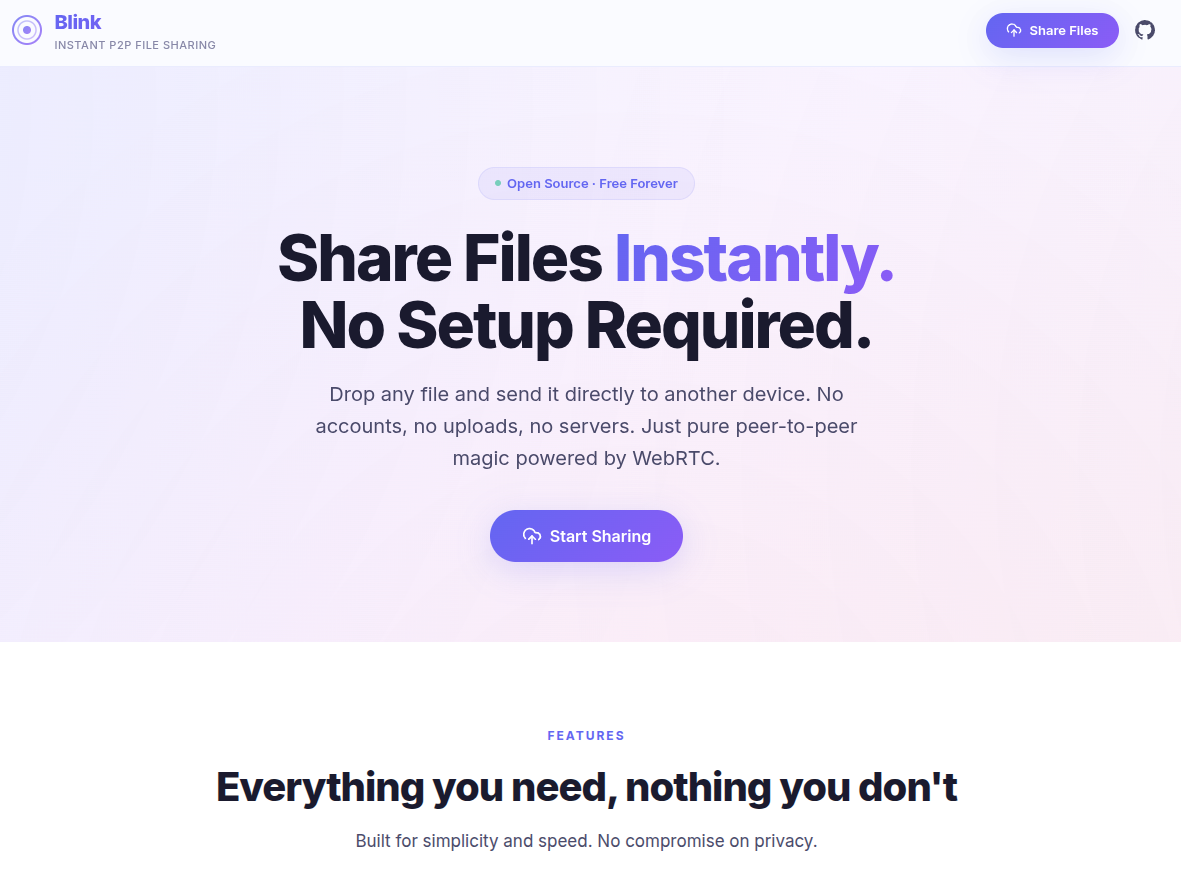
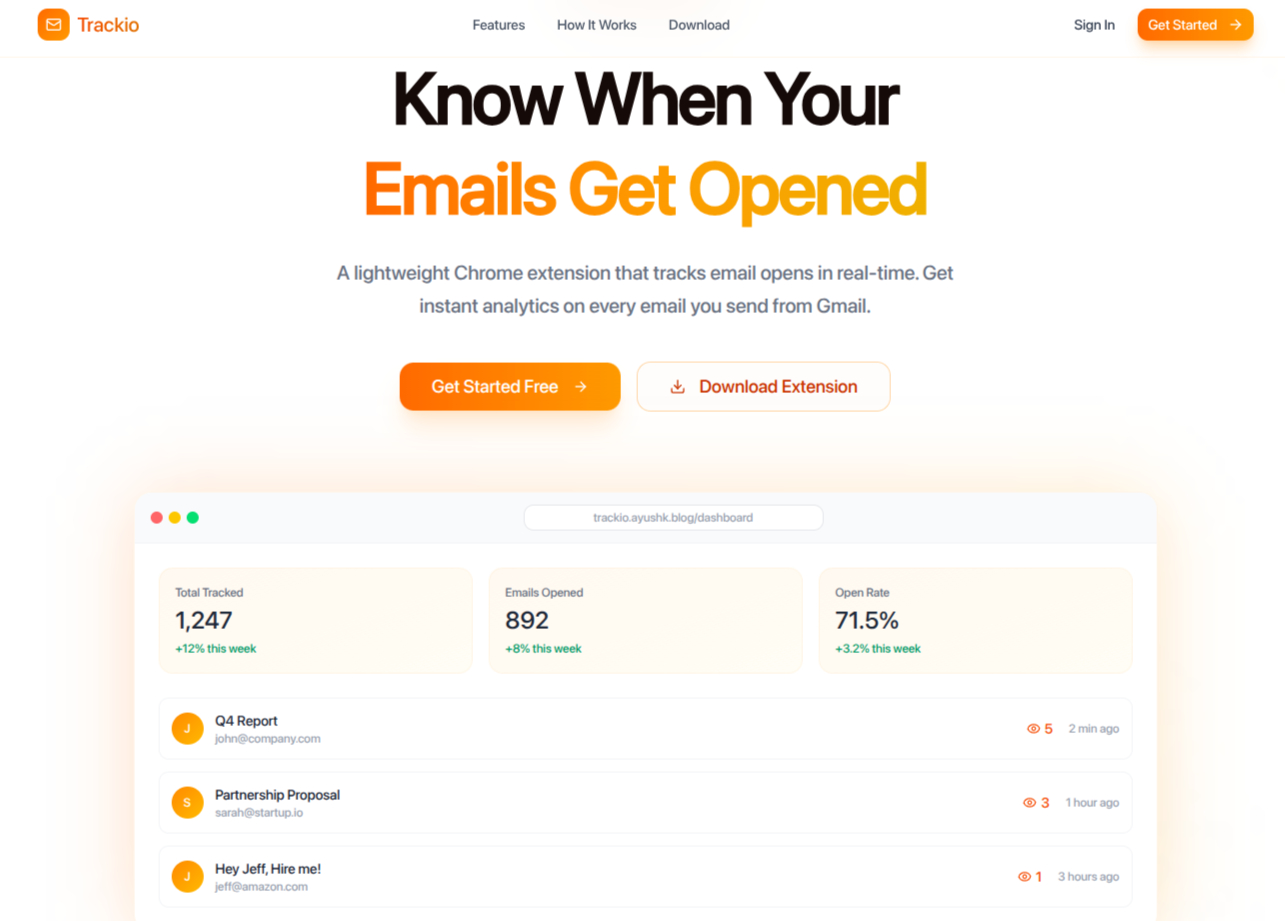
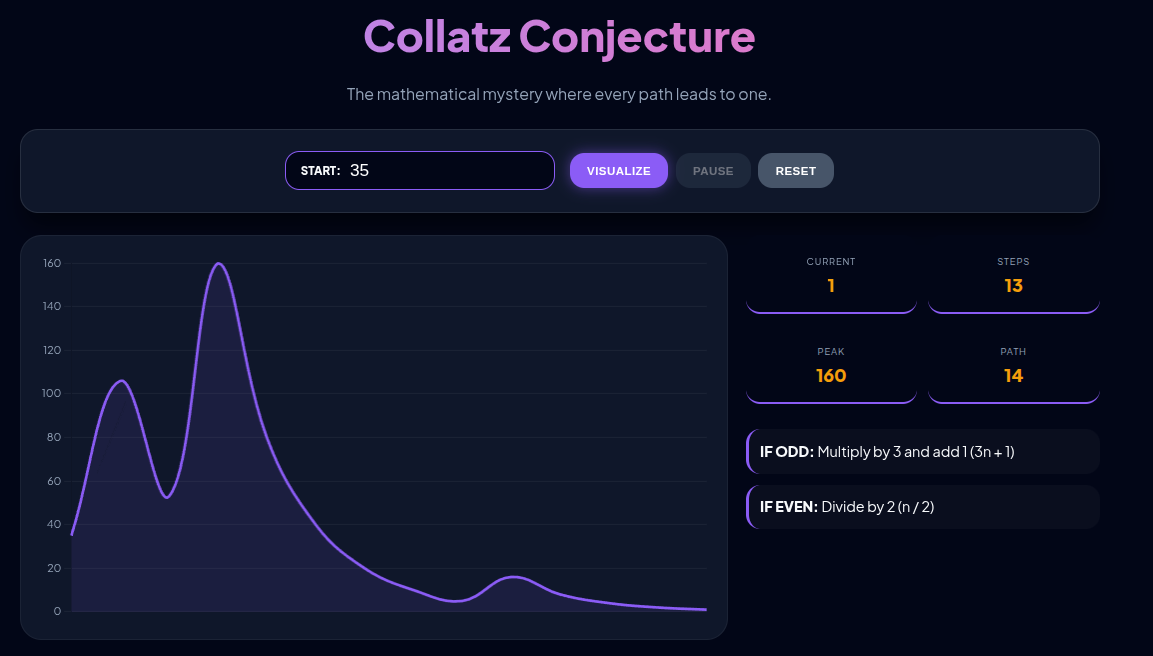
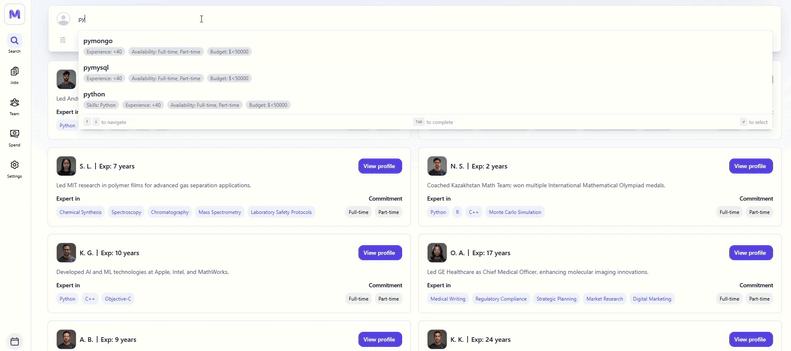
Typeahead System
A fast and efficient typeahead feature I built during my work trial at Mercor.
Get in Touch
Open to opportunities, projects, and interesting conversations. Connect via the socials below, or feel free to schedule an intro call.